The Stakes of Understanding AI Capabilities
In litigation involving artificial intelligence systems, one of the most critical—and most misunderstood—questions is deceptively simple: How good is this AI?
Whether you're defending against claims that an AI system made discriminatory decisions, pursuing intellectual property theft of machine learning models, or challenging vendor representations about system capabilities, the answer depends on understanding AI benchmarks. These standardized tests have become the primary way the AI industry measures and compares intelligence.
For attorneys, benchmarks function as a paper trail. They're the documented evidence of what a system could or couldn't do at a particular moment in time—critical for establishing timelines, refuting or supporting capability claims, and building evidentiary foundations for expert testimony.
What Are AI Benchmarks and Why They Matter
An AI benchmark is a standardized test designed to measure specific capabilities of an AI model. Unlike general intelligence tests, AI benchmarks are narrowly focused: they test whether a system can complete a specific task correctly, at scale, with documented results.
Think of benchmarks like standardized tests for students. A SAT measures reading, math, and writing across thousands of students, creating comparable scores. AI benchmarks measure things like code generation ability, mathematical reasoning, or conversational quality across thousands of test cases, producing comparable scores.
For litigation purposes, benchmarks matter because they:
- Create independent evidence: Rather than relying on vendor claims or cherry-picked examples, benchmarks provide third-party measurement data.
- Establish baselines: They show what the state-of-the-art was at a specific date, helping establish timeline evidence in IP cases or performance disputes.
- Enable comparison: Benchmarks allow you to compare one system against another using the same scoring methodology.
- Document limitations: Benchmarks reveal what systems cannot do, which is often more important than what they can do in litigation.
- Support expert testimony: Courts increasingly expect experts to cite benchmark data when making claims about AI capabilities.
The Key Benchmarks You Need to Know
Dozens of benchmarks exist, but several have become dominant in the industry and most frequently appear in litigation contexts. Here's what you need to know about each:
SWE-bench (Software Engineering Benchmark)
Measures whether an AI system can solve real-world software engineering tasks. The test involves analyzing GitHub repositories, identifying bugs or feature requests, and generating code fixes. Scores reflect the percentage of test cases resolved correctly.
Why it matters for litigation: SWE-bench is particularly relevant in IP theft cases involving software development tools, employment disputes over AI-assisted coding work, and product liability cases involving AI-generated code. If your case involves claims about code generation capability, SWE-bench scores become key evidence.
Terminal-Bench 2.0
Tests an AI system's ability to execute commands in command-line environments and achieve actual outcomes—not just predict what the output should be. This includes system administration tasks, file management, and environment-specific problem-solving.
Why it matters for litigation: Terminal-Bench is crucial in cybersecurity breach litigation, cases involving autonomous AI agents, and disputes over system administration tool capabilities. It separates theoretical knowledge from practical execution ability, which has profound implications for both defense and liability.
GPQA Diamond (Graduate-Level Google-Proof Question Answering)
Presents graduate-level physics, biology, and chemistry questions that are difficult to find answers to through web search. Measures deep domain expertise rather than retrieval of common knowledge. The "Diamond" variant is a filtered version containing only the hardest questions.
Why it matters for litigation: GPQA is essential in professional services disputes—particularly involving medical AI, legal research AI, or scientific advisory systems. It demonstrates whether a system has genuine expertise or merely retrieves and regurgitates information. This distinction is critical in malpractice cases and product liability disputes.
Chatbot Arena
An open crowdsourced platform where users submit prompts and vote on which of two AI responses is better. Over hundreds of thousands of user votes, a ranking emerges. Uses Elo rating system (same as chess rankings) for scoring. Provides real-world feedback on user experience rather than test-based metrics.
Why it matters for litigation: Chatbot Arena captures actual user preferences and experience quality, making it relevant in consumer protection cases, false advertising disputes, and employment discrimination claims involving AI chatbots. It's harder to dismiss as "not real-world" since the data comes directly from actual user comparisons.
Humanity's Last Exam
A benchmark created by the Center for AI Safety designed to test whether AI systems can reason at human expert level on questions across science, mathematics, history, and other domains. Specifically designed to be exceptionally difficult.
Why it matters for litigation: This benchmark is increasingly cited in testimony about whether AI systems can match human expert capabilities. It's particularly relevant in cases challenging vendor claims about expert-level performance or in disputes about whether AI can replace human professionals in specific domains.
How to Read Benchmark Scores
Benchmark scores come in different formats depending on the test. Understanding these formats is essential for credible expert testimony and effective cross-examination.
Percentage Scores (0-100%)
The most straightforward format: the percentage of test cases solved correctly. A 75% score on SWE-bench means the system solved 75 out of 100 test problems correctly.
Interpretation tip: Don't mistake this for overall accuracy. If a benchmark has 10,000 test cases, a 75% score means 7,500 were solved correctly. More importantly, understand that a 75% score does not mean the system is "75% as good as humans"—different benchmarks have different human baselines.
Human Baseline Comparisons
Most benchmarks include data on how humans perform on the same test. This contextualizes the AI score. A 60% AI score is meaningless without knowing if the human baseline is 70% or 95%.
Litigation implication: Always compare the AI score against the documented human baseline from the same benchmark. Marketing claims like "AI matches expert performance" often ignore the actual human baseline on that specific test.
Elo Ratings
Used in Chatbot Arena and similar head-to-head comparison benchmarks. Elo ratings are derived from the chess ranking system and represent relative strength in pairwise competitions. A 200-point difference in Elo rating typically means roughly 75% win rate for the higher-ranked player.
Interpretation tip: Elo ratings only measure relative ranking, not absolute capability. Two systems could both have high Elo ratings but both perform poorly on actual tasks. The value is in comparing systems to each other, not in determining if they're actually good.
Pass@k Scoring
Some benchmarks, particularly code generation tests, use "Pass@k" scoring: the system generates multiple solutions (k different attempts) and the test passes if any of them is correct. Pass@1 means the first attempt had to be correct; Pass@10 means any of the 10 attempts could be correct.
Critical for litigation: Pass@k is fundamentally different from Pass@1. A system with 40% Pass@1 but 70% Pass@10 seems far more capable when highlighting one metric than the other. Always demand clarity on whether you're looking at Pass@1 (what most users get) or Pass@k (what researchers measure).
Calibration Error
Measures how well a system's confidence predictions match its actual accuracy. A system might answer 85 questions and express 90% confidence in each—calibration error measures whether it was actually right about 90% of those.
Why it matters: In litigation, knowing whether a system's stated confidence is reliable is critical. A system that outputs answers with false confidence is more dangerous (and more negligent) than one that accurately acknowledges uncertainty. Calibration error should appear in expert reports on system behavior.
Reading AI Leaderboards: The Artificial Analysis Framework
Multiple websites aggregate benchmark results and rank AI systems. The most comprehensive for litigation purposes is Artificial Analysis, which synthesizes data from multiple benchmarks into a single scoring framework. Understanding how to read these leaderboards is critical for expert testimony.
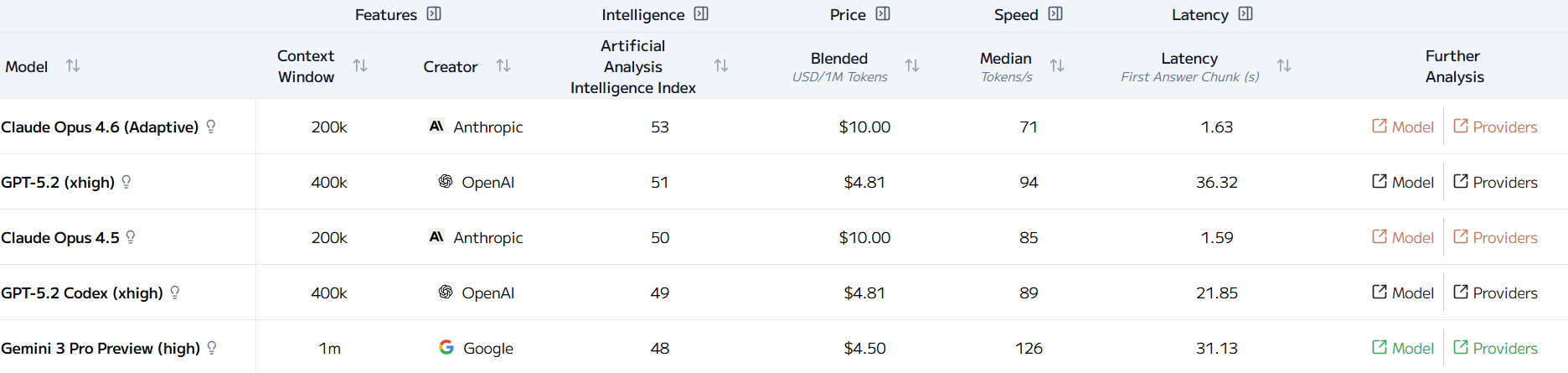
Artificial Analysis' Leaderboard Sorted by Intelligence Index (February 7, 2026)
Intelligence Index
Artificial Analysis's composite score of raw capability across diverse benchmarks. Combines performance on reasoning, code generation, factual knowledge, and other dimensions into a single number. Weighted toward more rigorous benchmarks.
For litigation: Use the Intelligence Index for general capability comparisons, but always drill down into the underlying benchmarks. The composite hides important details about where a system is strong and weak.
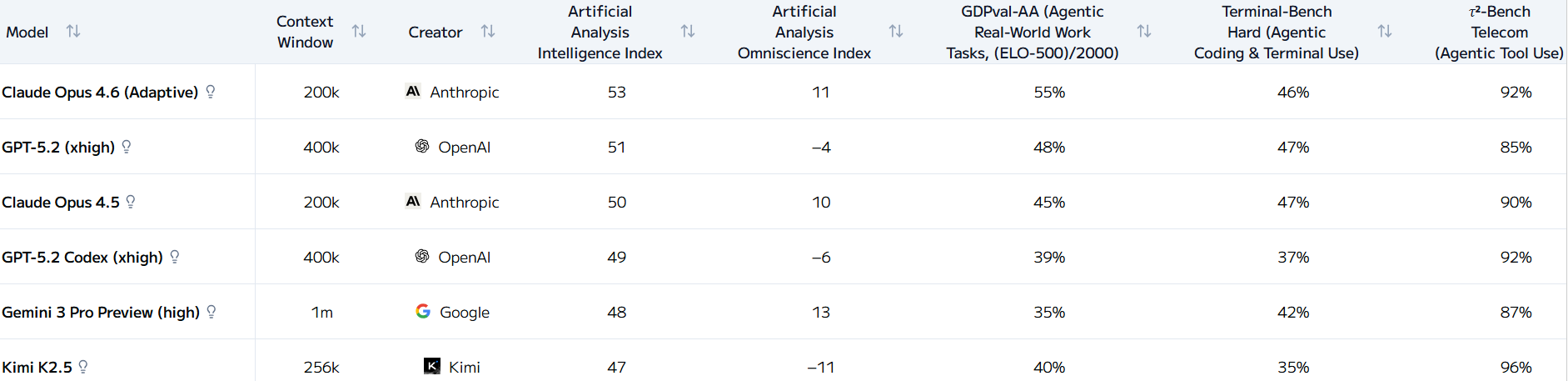
The Intelligence Index Components: How individual benchmarks contribute to the composite score
Omniscience Index
Focuses specifically on knowledge and information retrieval capabilities. Indicates how well a system performs on question-answering and factual knowledge tasks independent of reasoning complexity.
For litigation: Relevant in disputes about research tools, fact-checking systems, or AI assistants used in due diligence or investigative work.
GDPval-AA and Terminal-Bench Hard Rankings
Specialized indices for specific task domains. GDPval-AA measures real-world pragmatic reasoning. Terminal-Bench Hard shows performance on the most difficult terminal command tasks.
For litigation: These domain-specific rankings become critical when your case focuses on a particular type of work. If you're litigating about a system used for system administration, Terminal-Bench Hard ranking matters more than Intelligence Index.
Five Critical Questions to Ask in AI-Related Discovery
When you're involved in litigation where AI systems are central to the dispute, these five discovery questions should appear on your list. They force the other party to produce benchmark data or explain its absence.
1. What benchmarks were used to validate this system's capabilities? +
2. When these benchmarks were performed, what was the pass rate versus the human baseline? +
3. Has this system been tested on benchmarks relevant to the specific task it performed in this matter? +
4. What was the training data cutoff date, and does that affect the benchmark interpretation? +
5. Are there any benchmarks or tests on which this system performed poorly that are relevant to the claim? +
Where to Verify AI Benchmark Claims
Don't rely on vendor websites or press releases for benchmark data. These resources let you verify claims independently:
Artificial Analysis (artificial-analysis.com)
Comprehensive aggregation of benchmark results across models, with detailed breakdowns by benchmark and metric. Updated regularly. Most useful for comparing multiple systems across multiple benchmarks.
Chatbot Arena (arena.lmsys.org)
Direct access to crowdsourced comparison data. You can download the raw voting data and analyze it independently. Particularly useful because the data comes from actual user preferences, not researchers.
Epoch AI (epochai.org)
Database of AI system benchmarks with historical data. Useful for establishing timelines of when capabilities were documented and how they've evolved. Critical for IP cases involving questions about what was possible at a specific date.
Individual Benchmark Papers and Leaderboards
For specific benchmarks like SWE-bench, GPQA, or Terminal-Bench, go to the original benchmark paper and official leaderboard. These contain detailed methodology and can expose issues with how vendors are reporting results.
Understanding Benchmark Limitations
Benchmarks are tools, not absolute measures of intelligence. In litigation, understanding what benchmarks miss is as important as understanding what they measure. Several critical limitations affect how you use benchmark data:
Training Data Contamination
If an AI system was trained on data that included examples from a benchmark, it doesn't demonstrate learning—it demonstrates memorization. This is a known problem: several widely-cited systems have shown drops in performance when tested on newer, non-contaminated benchmarks.
For litigation: Always verify whether training data cutoff predates the benchmark or if contamination has been tested. A system trained on data through 2024 could have seen benchmark test cases during training, invalidating the benchmark as evidence of capability.
Benchmark Gaming and Overfitting
As benchmarks become popular, model developers optimize specifically for those benchmarks rather than general capability improvement. This means benchmark scores can rise without real-world performance improving. The system gets better at tests, not at actual work.
For litigation: Benchmark improvements that don't correlate with real-world usage improvements should raise red flags. Consider requiring testing on newer, unreleased benchmarks that can't have been optimized for.
Quality Control and Test Design Variability
Benchmarks vary dramatically in quality. A benchmark created by well-resourced research labs with careful peer review is more reliable than one created quickly with minimal validation. Some benchmark scores are based on human annotators who may not have expertise in the domain being tested.
For litigation: Demand details on how benchmarks were constructed, who validated them, and whether they've been peer-reviewed. A score on a hastily-designed benchmark is less powerful evidence than a score on a rigorous, published benchmark.
What Benchmarks Don't Measure
Benchmarks measure narrow capabilities on specific tasks. They don't measure:
- Robustness to adversarial or novel inputs outside training distribution
- Real-world latency, cost, or resource consumption
- Fairness across demographic groups (though some newer benchmarks do test this)
- Truthfulness or tendency to hallucinate
- Long-context understanding and reasoning
- Multimodal reasoning (combining text, images, video)
- Common sense reasoning in ambiguous real-world situations
High benchmark scores don't guarantee a system is safe, fair, or reliable in deployment. They measure specific capabilities, period.
General Acceptance Questions
In litigation, you may face challenges to benchmark evidence as lacking "general acceptance" in the relevant field. While benchmarks are increasingly standard in AI research, some judges and juries may be unfamiliar with them. This argues for pairing benchmark evidence with expert testimony that explains the methodology and limitations.
Practical Implications for Different Practice Areas
How benchmarks matter differs significantly depending on the type of litigation. Here's how different practice areas should approach benchmark evidence:
Intellectual Property Litigation
In patent disputes involving AI systems, trade secret misappropriation claims, or copyright infringement, benchmarks establish the state of the art at specific dates. If you're arguing that a competitor's system is impermissibly similar to yours, benchmark scores at the time of development help establish what was technologically possible. They also help establish whether claimed innovations represented genuine advancement or merely followed a linear progression visible in public benchmarks.
Discovery strategy: Request all internal benchmark testing, all dates systems were compared to public benchmarks, and all technical reviews analyzing competitive systems' published performance.
Employment Discrimination and Algorithmic Bias
Benchmarks increasingly include fairness metrics measuring performance disparities across demographic groups. While most mainstream benchmarks still focus on overall accuracy, specialized benchmarks like those from the AI Now Institute and related research examine whether systems perform differently for protected classes. These benchmarks become critical evidence in discrimination cases.
Discovery strategy: Request not just aggregate benchmark scores but disaggregated performance by demographic group. Request any fairness testing, bias audits, or equal opportunity analyses performed before deployment.
Product Liability and Negligence
In cases involving AI systems that caused harm—medical AI that missed diagnoses, autonomous systems that caused injuries, or automated systems that made harmful decisions—benchmarks help establish whether the system was operating at expected capability levels when the harm occurred. They also establish whether the developer knew about capability limitations that should have triggered warnings.
Discovery strategy: Request benchmark testing specific to the actual use case, internal known limitations documentation, and benchmark comparisons to alternative systems that might have been safer.
Regulatory Compliance Matters
In disputes with regulators about AI system adequacy or compliance, benchmarks provide objective evidence of capability. Regulators increasingly expect organizations to benchmark their systems against public standards before deployment in regulated contexts. Having—or lacking—benchmark testing becomes evidence of reasonable (or negligent) implementation.
Discovery strategy: Request all regulatory compliance documentation, internal discussions of whether benchmarking was required, and any requests from regulators for capability evidence.
Building Your Benchmark Toolkit: Practical Guidance for Legal Teams
If you're handling multiple AI-related cases, building your own benchmark database becomes valuable. Here's how to approach it systematically:
Start with a Baseline Inventory
Create a simple spreadsheet with the major benchmarks: SWE-bench, Terminal-Bench, GPQA, Chatbot Arena, and any domain-specific benchmarks relevant to your practice area. For each, record:
- Benchmark name and domain (code, reasoning, knowledge, etc.)
- Most recent public leaderboard scores for major AI systems
- Human baseline performance (if available)
- Date last updated
- Link to official leaderboard or paper
This becomes a reference you can quickly consult when a case involves capability claims about particular AI systems.
Identify Benchmarks Relevant to Your Practice Areas
If you handle employment law cases, identify benchmarks measuring reasoning on legal documents and employment scenarios. If you handle IP cases, focus on code generation and source code analysis benchmarks. Domain-specific benchmarks often exist and provide more relevant evidence than general-purpose ones.
Track Historical Benchmark Data
Artificial Analysis and Epoch AI provide snapshots of historical benchmark performance. Set a reminder to review them periodically and archive benchmark scores quarterly. This creates a historical record that becomes essential when you need to establish what was possible at a specific date in the past.
Develop Standard Discovery Questions on Benchmarks
Incorporate benchmark-focused discovery questions into your standard AI-related case templates. The five questions mentioned earlier should be a baseline, but expand them with domain-specific questions based on your practice area.
Establish Expert Relationships with Benchmark Authors
Many benchmark creators are academics or researchers actively working in AI research institutions. Developing relationships with experts who understand specific benchmarks deeply can be valuable for getting detailed explanations of methodology, known limitations, and proper interpretation of results.
Looking Ahead: How Benchmarks Will Evolve
The landscape of AI benchmarks is rapidly evolving. Understanding where it's heading helps you anticipate what evidence will matter in future litigation:
Shift Toward Real-World Benchmarks
Next-generation benchmarks increasingly test systems in real-world environments rather than controlled test conditions. Terminal-Bench 2.0 represents this shift—it tests whether systems can actually accomplish work in actual command-line environments, not just predict what the output should be. We'll see more benchmarks that measure actual task completion in realistic contexts.
Implication for litigation: Real-world benchmarks will become more persuasive evidence because they measure what actually happens, not theoretical capability. Expect courts to increasingly prefer benchmarks testing real-world performance over theoretical test performance.
Specialization of Fairness and Bias Benchmarks
As discrimination and algorithmic bias litigation grows, specialized benchmarks measuring fairness and performance disparities across demographic groups will become standard. Several organizations are developing these now, and they'll likely become as routine as accuracy benchmarks within five years.
Implication for litigation: In discrimination cases, expect fairness benchmarks to become standard discovery. Organizations that haven't conducted fairness benchmarking will face heightened scrutiny.
Faster Release of New Benchmarks
Benchmark release cycles are accelerating. New benchmarks for emerging AI capabilities are published monthly. This creates both opportunity and risk: opportunity to test novel capabilities quickly, but also risk that systems are optimized for benchmarks faster than new relevant tests can be deployed.
Implication for litigation: Monitor emerging benchmarks closely. A competitor's system that performs well on a 3-month-old benchmark might perform poorly on a newly-released test for the same capability category, exposing overfitting or gaming.
Development of Scenario-Based Benchmarks for Regulatory Compliance
Regulators are beginning to develop their own benchmarks to test AI system compliance with regulatory requirements. The SEC, FDA, and FTC are all exploring how to benchmark compliance. This will create new categories of benchmark evidence relevant to regulatory disputes.
Implication for litigation: In cases involving regulatory compliance, government-developed benchmarks will gain credibility as objective evidence of compliance or non-compliance.
The Bottom Line: Benchmarks as a Paper Trail
In the end, AI benchmarks serve a simple purpose in litigation: they create a paper trail. They document what AI systems could and couldn't do at specific moments in time. They provide objective, third-party measurements rather than relying on vendor claims or cherry-picked examples.
For attorneys, benchmarks are particularly valuable because they:
- Establish timelines and historical capability
- Enable comparison between systems using consistent methodology
- Identify gaps and limitations in AI capabilities
- Provide foundation for expert testimony on system behavior
- Create pressure for full disclosure of system capabilities and limitations
Understanding how to read, interpret, and challenge benchmark claims is becoming as essential to AI litigation as understanding statistics is to class certification disputes or data analysis is to antitrust cases.
The attorneys and firms that master benchmark interpretation early will have a significant advantage in AI-related litigation. Those who ignore benchmarks or treat them as marketing numbers will struggle to build credible technical arguments about AI capabilities.
Related Resources
Want to go deeper on AI litigation and AI system analysis? Check out these resources:
A comprehensive guide to investigating AI systems in litigation and regulatory contexts. Published by Chapman and Hall/CRC, 2026.
Expert analysis of AI systems for litigation, investigation, and regulatory compliance matters.
Regular insights on AI, litigation, and technology. Subscribe on LinkedIn for the latest analysis on AI benchmarks and system analysis.
Stay Updated on AI Litigation and Technology
Get regular insights on AI benchmarks, litigation strategy, and expert analysis delivered to your inbox.
Subscribe to Beyond the Algorithm